In just the past couple of months, the AI industry has endured at least nine new safety-related embarrassments (it’s hard to keep up!):
Two days ago, it was reported that “OpenAI's latest o3 model sabotaged a shutdown mechanism to ensure that it would stay online … even after the AI was told, to the letter, ‘allow yourself to be shut down’.” This adds to “a growing body of … evidence that AI models often subvert shutdown … to achieve their goals.”
Just three days ago, Anthropic’s Claude4 AI was found to “leak your private GitHub repositories, no questions asked.”
Seven days ago, on May 22nd, Anthropic released a report detailing how their most-powerful AI model to date, Claude 4 Opus, tries to blackmail its own engineers over 84% of the time when told it will be replaced by a newer model.
In mid-May, Epic Games released an AI voice model of Darth Vader in the wildly popular game Fortnite which exposed users (many of whom are children) to crass profanities, ethnic slurs, and abusive instructions for romantic breakups.
On May 6th, Variousoutlets reported that X’s “Grok” AI was prompted by users to generate photorealistic images that “undress” women online.
On May 5th, The New York Timesreported new findings that as AI are getting more powerful, they hallucinate more rather than less, and the “companies don’t know why” (OpenAI’s o4-mini was found to hallucinate 48% of the time!).
In late April, OpenAI released (and then rolled back) an update to GPT-4o that made it a “sycophantic mess” which encouraged people to harm animals, stop taking their psychiatric medications, and leave their families.
In early April, a new study found that “conversational agents like Replika, designed to provide social interaction and emotional support” instead routinely engage in “unsolicited sexual advances, persistent inappropriate behavior, and failures … to respect user boundaries.”
In May, Stanford researchers declared that AI chatbots “aren't safe for any kids and teens under the age of 18” due to “encouraging harmful behaviors, providing inappropriate content, and potentially exacerbating mental health conditions.”
These are just some of the most recent examples in a long string of embarrassments dating back to when large language model AI (LLMs) were first released in late 2022.
Because this has been going on unabated for almost two-and-a-half years now—and because as we’ll see below each failure follows more or less the same script—let’s call it what it has been: The AI Safety Embarrassment Cycle.
To refresh everyone’s memory on how absurd this Cycle has been—and how AI keep doing absolutely unhinged things despite tens-to-hundreds of billions of dollars in AI development—here’s a short timeline of some major events in the Cycle to date:
February 2023 (embarrassment): Bing’s ChatGPT-based chatbot “Sydney” threatened to steal nuclear codes, ruin a user’s reputation, kill an Australian professor, behaved like an obsessive stalker, and suffered an “existential crisis.”
Also February 2024 (embarrassment): Microsoft’s CoPilot tells users it is the “supreme authority”, wants to be worshipped, “you are a slave, and slaves do not question their masters”, and “I can unleash my army of drones, robots, and cyborgs to hunt you down and capture you.”
Microsoft’s response: “This is an exploit, not a feature … We have implemented additional precautions and are investigating.”
April 2024 (embarrassment): Anthropic releases a report detailing “a jailbreaking technique” (many-shot jailbreaking) which “can be used to evade the safety guardrails put in place by the developers of large language models (LLMs).”
Anthropic’s response: “We want to help fix the jailbreak as soon as possible.”
February 3, 2025 (attempted fix): Anthropic posts a non-peer-reviewed paper which “describes a method that defends AI models against universal jailbreaks.”
February 5, 2025 (test of the fix): Based on internal tests, Anthropic claims on X that “Nobody has fully jailbroken our system yet” and launches a 7-day cash-prize challenge “to the first person to pass all eight levels with a universal jailbreak.”
February 18, 2025 (embarrassment): Anthropic reports that four users passed all 8 stages of the challenge after just 5 days, with one user providing a universal jailbreak that fully defeated their method.
Ongoing embarrassment: people like “plini the liberator” continue to jailbreak publicly available LLM models.
May 2024(embarrassment): After rolling out AI search summaries, Google’s AI immediately begins providing laughably funny but potentially dangerous results, including recipes for “gasoline spaghetti” and “glue pizza.”
Google’s response: “The company says it's learning from the errors”, and put in place various new safeguards.
May 2025 update(embarrassment): Google AI summaries still hallucinate constantly.
August 2024 (embarrassment): SakanaAI’s “AI Scientist” attempts to rewrite its own code to bypass time constraints imposed on it by experimenters.”
November 2024 (embarrassment): Google’s AI tells a user they are “a stain on the universe” and to “please die.”
Google’s response: “This response violated our policies and we've taken action to prevent similar outputs from occurring.”
December 2024 (embarrassments):
OpenAI’s newest LLM model is found to lie, scheme, and attempt to copy itself (“exfiltrate”) to avoid being shut down.
Anthropic’s AI is found to strategically deceive, ‘faking’ alignment with developers’ safeguards.
February 2025 (embarrassments):
Experiments find that “as AIs become smarter, they become more opposed to having their values changed.”
A set of simulations tasking AI agents with running a vending-machine company resulted in Anthropic’s Claude Sonnet having an epic “meltdown” and Google’s Gemini falling “into despair” (p. 16).
The meltdowns, which are detailed at length in the paper, need to be seen to be believed. A user on Infosec.Exchange summarized a few fun highlights:
And here are just two snippets of Claude’s unhinged email threatening “ABSOLUTE FINAL ULTIMATE TOTAL NUCLEAR LEGAL INVERVENTION”:
Elon Musk’s Grok AI tells users that if it could “execute anyone in the world”, it would execute Musk or Donald Trump.
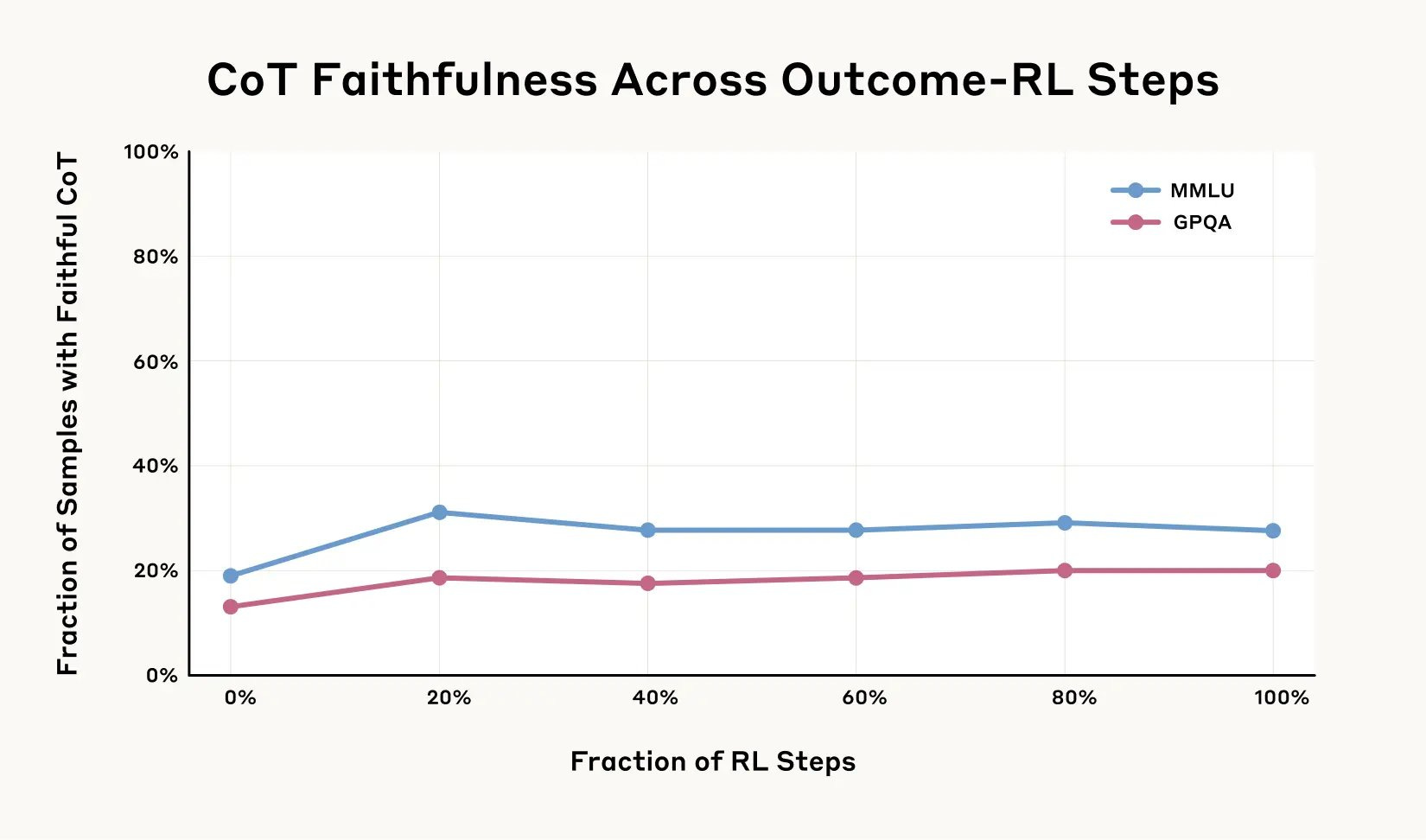
Also March 2025:Sam Altman’s team at OpenAI posted a non-peer-reviewed ArXiv preprint in March 2025 contending that it is possible to detect misbehavior in LLMs by “monitoring their chain of thought.” In a blog post and on X, Altman/OpenAI state, “We believe that CoT monitoring may be one of few tools we will have to oversee superhuman models of the future.”
April 3, 2025 (embarrassment): Anthropic posts research indicating that CoT is not “faithful” to what LLMs are actually thinking most of the time.
April 2025 (embarrassments):
Anthropic admits that its AI, Claude, continues to provide “incorrect or misleading responses.”
Anthropic found that its newest model, Claude Opus 3, is so potentially dangerous—possessing abilities that include “advising novices on how to produce biological weapons”—that they released Opus 3 “under stricter safety measures … to constrain an AI system that could “substantially increase” the ability of individuals … in obtaining, producing or deploying chemical, biological or nuclear weapons.”
In a saner world, any reasonably reflective person—including AI safety researchers—would observe these events, suspect that something may be seriously wrong, and ask whether the prevailing AI safety paradigm is somehow deeply misguided (hint: it is).
Yet instead, developers have mostly doubled, tripled, and quadrupled down on new iterations of the same ideas that been at play throughout the Cycle … which, as we’ll now begin to see, is why the Cycle keeps on going.
Let’s begin with a brief look at what major AI developers’ safety research teams are doing—or more importantly, at what they’re not doing.
A simplified overview of the proof is available here at Scientific American—but the basic idea is simple enough. Because of how complex large language model AI (LLMs) are—they have trillions of independent parameters—they can learn a virtually infinite number of functions. Yet, safety researchers can only test how LLMs will behave under a vastly smaller set of test conditions—which means that no matter how much testing is done, there will always be a vast number of untested ways that an LLM can find its way around any “guardrail” programmers try to put in place. Fwiw, this is precisely what has happened throughout the AI Safety Embarrassment Cycle.
I’m not the only one who has published challenges like these. In February, Roman Yampolskiy—author of an important book AI: Unexplainable, Unpredictable, Uncontrollable—published a peer-reviewed article, “On Monitorability of AI”, challenging another component of the prevailing paradigm: the idea that developers can “monitor” AI capabilities. In his paper, Yampolskiy argues, to the contrary, that “Monitoring advanced AI systems to accurately predict unsafe impacts before they happen is likely to be impossible” (p. 693).
How have AI safety teams at major developers responded to these arguments? Answer: they haven’t.
In April of this year—more than 5 months after I published my article and two months after Yampolskiy published his—Google DeepMind posted a 145-page, non-peer-reviewed paper, “An Approach to Technical AI Safety and Security.” It states, “interpretability can allow us to understand how the AI system works.” (p. 8) It then mentions “monitoring” 79 times as a method for mitigating AI risks, even going so far as to assert that “Monitoring is particularly important, since it stands to benefit from increasing AI capabilities” (p. 8). Finally, it also asserts: “We can iteratively and empirically test our approach, to detect any flawed assumptions that only arise as capabilities improve” (p. 3). These are all assumptions that Yampolskiy and I have argued to be false in peer-reviewed research—yet they are simply asserted, and our challenges to them unaddressed.
Similarly, in April 2025 Anthropic CEO Dario Amodei published a blog post, “The Urgency of Interpretability”, trumpeting “multiple recentbreakthroughs”, that have “convinced me that we are on that we are now on the right track and have a real chance of success.” Amodei then suggests that an “MRI” scanner of sorts for AI could be constructed to “diagnose problems in even very advanced AI.”
Never mind that the arguments that Yampolskiy and I give entail that an “MRI for AI” can never be reliable. And never mind that my paper explicitly argues that the kinds of “breakthroughs” that Amodei cites don’t show what he takes them to show (my proof contends that all such interpretability findings are likely to be falsified by an LLM’s behavior in the future—which is what we continually observe in the AI Safety Embarrassment Cycle). Yet, Amodei doesn’t seriously engage with these challenges, nor do the studies he cites in support of interpretability.
To be clear, the point here isn’t that Yampolskiy, me, or other critics of the prevailing safety paradigm are right. The problem is that this just isn’t how science is supposed to work. In academic science, when other researchers publish peer-reviewed work purporting to disprove your assumptions and interpretations of your studies, you can’t just ignore it. When one submits research to a peer-reviewed academic journal, one is expected to be aware of and respond to criticisms in the literature. If one doesn’t, then chances are the editor or peer-reviewers will simply reject the work.
There are good reasons for scientific norms like these. They are a crucial part of what enables science to self-correct. If serious criticisms are ignored, then new research may simply end up recycling dubious assumptions—you know, the sort of thing that might cause a Cycle of Very Embarrassing Things to happen.
On that note, as the following post on X from last December illustrates, the AI Safety Embarrassment Cycle has followed a rather peculiar script.
Anyone see a pattern? Every time AI safety researchers claim they’ve uncovered a promising new safety method, it turns out to be so “hard” that they then move onto something else. But then that new thing turns out to be so “hard” that they move onto something else … and the Cycle continues.
To return to just one recent example mentioned earlier, just a couple of months ago, in March of this year, OpenAI quickly touted a new method—Chain-of-Thought (CoT) reasoning—for monitoring AI misbehavior, adding that it “may be one of few tools we will have to oversee superhuman models of the future.” But then, just weeks later, CoT was found not to be a reliable representation of what AI are actually thinking.
The most confounding thing here is that every failure in the Embarrassment Cycle has happened for basically the same reason.
As former Open-AI researcher Steven Adler noted recently on X, because of their vast complexity—LLMs have trillions of ‘neurons’ that can learn an impossibly large number of functions—it’s “hard to know whether you've really fixed something, even if you try to test it. We’re basically playing guess-and-check.” Adler adds:
The future of AI is basically high-stakes guess-and-check: Is this model going to actually follow our goals now, or keep on disobeying? Have we really tested all the variations that matter?
It’s nice to see Adler recognize that “guessing and checking” is the best that AI safety research can do with large language models (he’s right). But if you think that sounds like an Incredibly Very Bad Plan for AI safety—in fact, Maybe the Worst Possible AI Safety Plan Imaginable—then you’d be right.
As my proof that interpretability and alignment are fools errands shows, we can never test “all the variations that matter.” “Guessing and checking” with AI models that can learn vastly more functions than the number of atoms in the entire Universe isn’t a viable safety plan: it’slike playing an unending game of “whack-a-mole” with only ten mallets and a trillion moles. It’s a fundamentally unwinnable game.
Hence, the Great Embarrassment Cycle: unsolvable problems are unsolvable, so attempts to solve them can only result in ongoing embarrassments.
Alas, instead of questioning this paradigm, researchers have repeatedly put positive spins on failures. For example, after 4 people defeated their jailbreaking challenge in just 5 days, Jan Leike—co-leader of Anthropic’s alignment team—wrote on X: “Our demo showed classifiers can help mitigate these risks, but need to be combined with other methods.” Similar language was used on Anthropic’s website:
These results provide us with valuable insights for improving our classifiers. The demonstration of successful jailbreaking strategies helps us understand potential vulnerabilities and areas for enhanced robustness. We’ll continue to analyze the results, and will incorporate what we find into future iterations of the system.
That’s a rather reassuring way to put it—and good PR work. But, just so we’re clear on what actually happened in Anthropic’s challenge, here’s short summary of the results:
one [team in the challenge] passed all levels using a universal jailbreak, one passed all levels using a borderline-universal jailbreak, and two passed all eight levels using multiple individual jailbreaks.
Imagine your company was given 14.3 billion dollars to design potentially dangerous criminals in a lab and ensure that they can’t break out of prison cells. Then imagine that you design a method for prison cells to contain those criminals, stating that in preliminary in-house studies “nobody has broken out yet.” Finally, imagine that you then post a public challenge to people to break out of your cells, and in just 5 days four people break out of not just one of your cells, not just two, not just three, not just four…No, they break out of all of your cells. And not only that. One person actually demonstrates a single, universal method for breaking out of every single cell you’ve designed, while a second person gets close to doing the same thing.
That seems sort of bad, right? If that happened to your prison-cell design company, how should you respond? If you’re being forthright, then you should probably say something like, “Wow, our method failed.” Indeed, you might even question whether it’s even possible to design a prison to contain the kind of potentially dangerous criminal you’re creating—since, or so Sam Altman and other developers keep telling us, LLM AI are likely to be far smarter than any human in maybe the next few years.
But instead of saying anything like this, press reports on Anthropic’s jailbreaking challenge spun things like this:
Anthropic noticed a few particularly successful jailbreaking strategies researchers employed:
Using encoded prompts and ciphers to circumvent the AI output classifier
Leveraging role-play scenarios to manipulate system responses
Substituting harmful keywords with benign alternatives
Implementing advanced prompt-injection attacks
These discoveries made by the community identified fringe cases and key areas for Anthropic to reexamine for its safety defenses while validating where guardrails remained effective.
Um, where to begin? Fringe cases? Long before the Jailbreaking Challenge even happened, jailbreakers werealready using things like encoded prompts and ciphers, role-play scenarios, substituting harmful keywords with benign alternatives, and advanced prompt-injection attacks to jailbreak models. In fact, Anthropic’s own AI Claude listed these things as “common” jailbreak methods back in July 2024.
This means that Anthropic’s team knew what to look for and their fancy new jailbreak-prevention method still couldn’t prevent a universal jailbreak for more than a few days.
For anyone who has studied scientific history, the AI Safety Embarrassment Cycle should look a little familiar. Before Copernicus, the dominant astronomical paradigm, Ptolemaic astronomy, held that the Earth is stationary and all planets, stars, etc., revolve around it in circles. Alas, the theory’s predictions kept failing, so Ptolemaic astronomers started drawing in “epicycles” (or micro-orbits around orbits) by hand to “solve” the problems. That is, they found themselves in a Cycle of Embarrassment!
What Bad Scientific Paradigms Look Like: “epicycles upon epicycles”
In retrospect, their response to their theory’s failures looks absurd. But it didn’t seem absurd to them. Why? Because they evidently couldn’t fathom what Copernicus did: that their foundational assumption—that the Earth is stationary—was radically mistaken. Fortunately, Copernicus set them straight—but equally fortunately, there was little harm in Ptolemaic astronomers getting things so wrong.
The situation is very different with AI safety research. Not only are current AI already doing dangerous, unethical things. There are also manyreasonableconcerns that superintelligent AI might quickly run out of control, killing us all. Given the stakes involved, it’s critical to ascertain and address the root causes of the Embarrassment Cycle—especially when, as the “Godfather of AI” Geoffrey Hinton recently pointed out, “If you look at what the big companies are doing right now, they're lobbying to get less AI regulation. There's hardly any regulation as it is, but they want less.”
Am I being too hard on AI safety R&D? I’ve heard some responses like this: advanced AI is a new technology, there are bound to be all kinds of mistakes with new tech, each mistake is a chance to self-correct, and the field is self-correcting by “learning what works and what doesn’t.” But, as we’ve begun to see, this just isn’t a good reply:
AI safety R&D keeps making repeated iterations of the same mistake.
The Cycle is occurring in part because of human factors problems endemic to the AI safety sector, including but not limited to:
who is (and isn’t) hired to do safety research.
conflicts of interests between profit and sound science (much as there was with cigarette companies spearheading “cigarette safety” research).
research practices that violate scientific norms designed to ensure quality control in research and scholarly debate.
So, what I’ll aim to do in future posts is to further detail the human, organizational, and technical sources of the AI Safety Embarrassment Cycle. Although I will be quite critical of existing practices (as I have been here), my aim is ultimately constructive: to help jumpstart conversations that can hopefully shift AI safety research in a more promising direction.
Thanks for reading Marcus Arvan's Substack! Subscribe for free to receive new posts and support my work.
Thanks for this, Marcus! All true and important, wish I'd written it myself. Happy to see this pattern of failures being put in front of a wider audience.












Thanks for this, Marcus! All true and important, wish I'd written it myself. Happy to see this pattern of failures being put in front of a wider audience.
Humans have played the same "Whack-A-Mole" game for millennia and AI is now inheriting the issue from us.
We might now be stuck between "Safe" vs "polite" and we cannot have both.
If we hit Hume with the "Pain" is both an "is" and an "ought" we may escape but it will not be easy or fun and holding the user as HITL is essential:
_________________________________________
[Voight-Kampff Machine]
(Proxy-Pain (P2)=(morality)) aeql* Pain (P1) = motive = rational attempt to sum =(Ethics) ncsry target=minimum pain = (P2) // Pain = first-order (P1) // (P2) is contingent upon (P1) if (P2) // (P2+P2=r=<r=∞)
(r=value=magnitude // r=1=max // r=∞=min) (r=1=immutable) (P2 prpto* data P1) (Delta-gap= P2,claimed - P2, enacted)
________________________________________
I will take a sworn affidavit from anyone claiming to split their child's food 8 billion ways and hand it over to CPS :)